Week 6 Concordancing with R
This tutorial introduces how to extract concordances and keyword-in-context (KWIC) displays with R. The aim is to show and exemplify selected useful methods associated with concordancing.
In the language sciences, concordancing refers to the extraction of words from a given text or texts (Lindquist 2009, 5). Commonly, concordances are displayed in the form of keyword-in-context displays (KWICs) where the search term is shown in context, i.e. with preceding and following words. Concordancing are central to analyses of text and they often represents the first step in more sophisticated analyses of language data (Stefanowitsch 2020). The play such a key role in the language sciences because concordances are extremely valuable for understanding how a word or phrase is used, how often it is used, and in which contexts is used. As concordances allow us to analyze the context in which a word or phrase occurs and provide frequency information about word use, they also enable us to analyze collocations or the collocational profiles of words and phrases (Stefanowitsch 2020, 50–51). Finally, concordances can also be used to extract examples and it is a very common procedure.
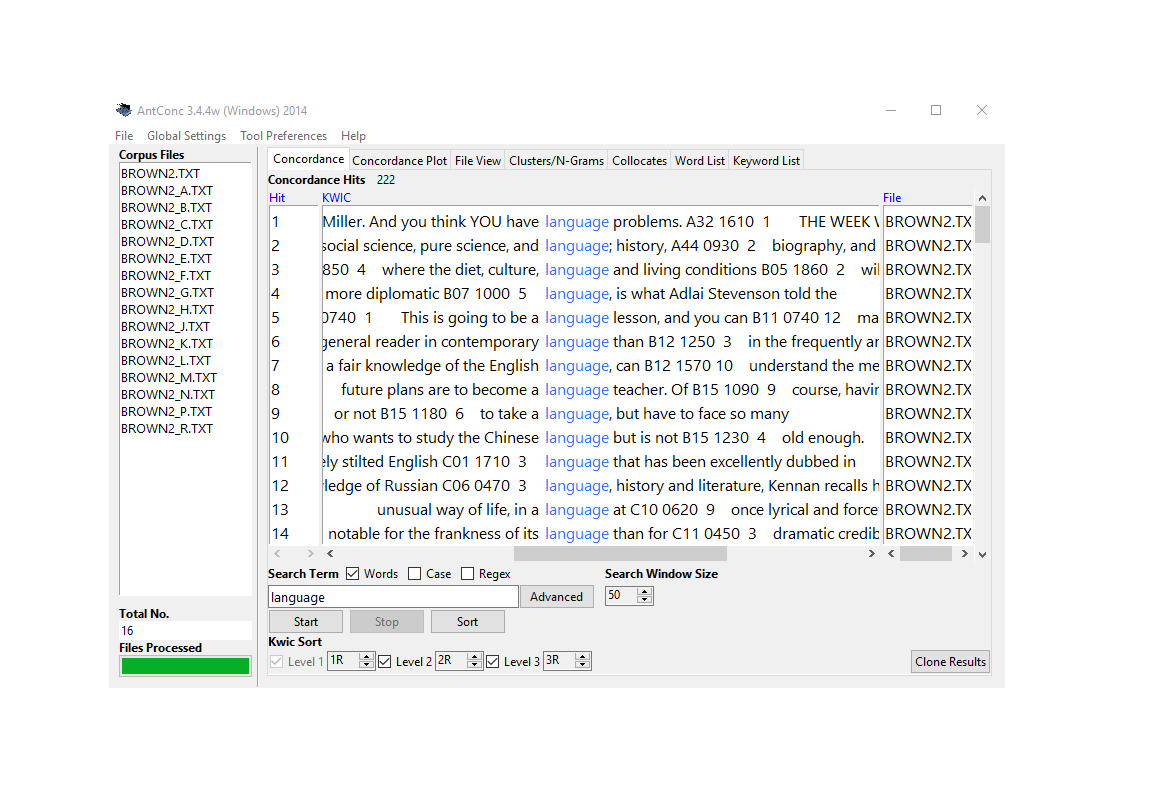
Figure 6.1: Concordances in AntConc.
There are various very good software packages that can be used to create concordances - both for offline use (e.g. AntConc Anthony (2004), SketchEngine Kilgarriff et al. (2004), MONOCONC Barlow (1999), and ParaConc Barlow (2002)) and online use (see e.g. here).
In addition, many corpora that are available such as the BYU corpora can be accessed via a web interface that have in-built concordancing functions.
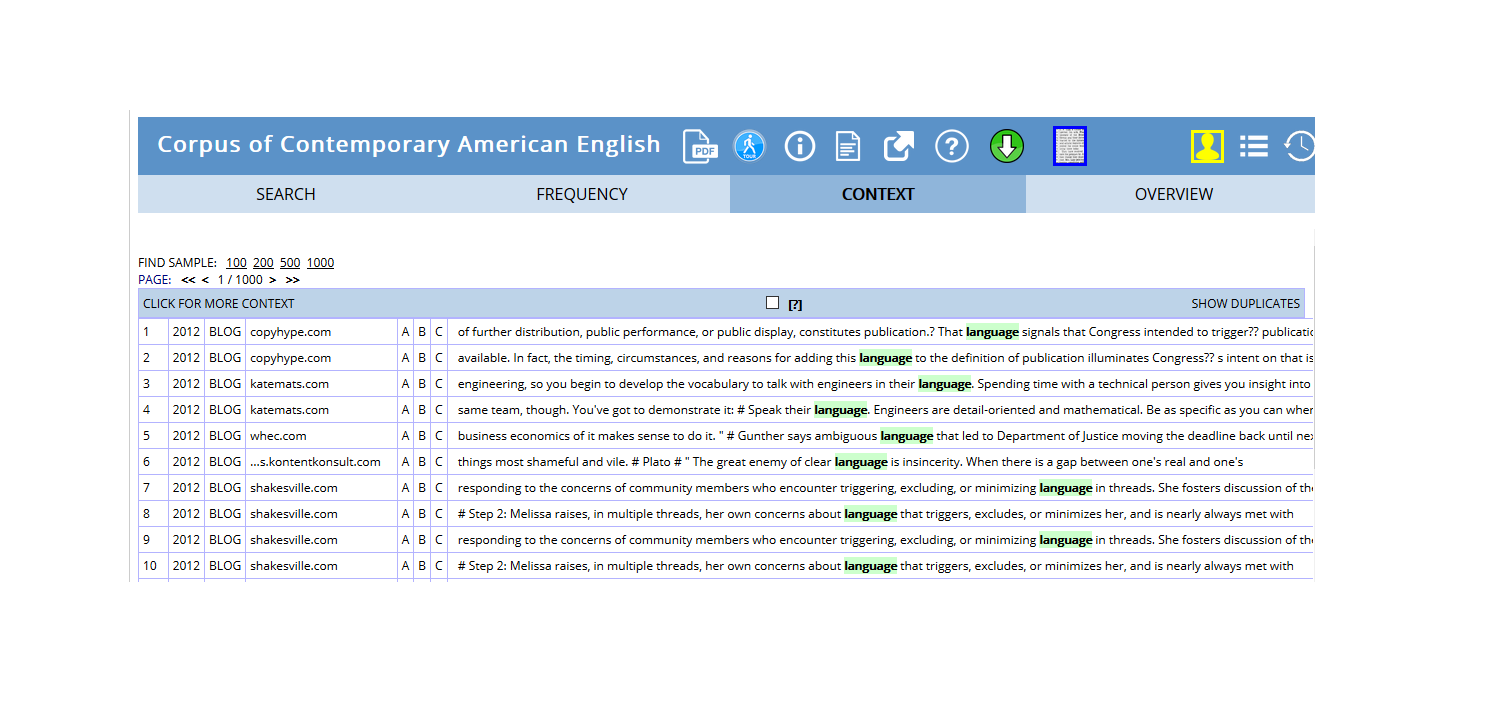
Figure 6.2: Online concordances extracted from the COCA corpus that is part of the BYU corpora.
While these packages are very user-friendly, offer various useful functionalities, and almost everyone who is engaged in analyzing language has used concordance software, they are less flexible and less transparent then R.
Preparation and session set up
For this tutorials, we need to install certain packages from an R library so that the scripts shown below are executed without errors - it may take some time (between 1 and 5 minutes to install all of the libraries so you do not need to worry if it takes some time).
# install packages
install.packages("quanteda")
install.packages("tidyverse")
install.packages("gutenbergr")
install.packages("flextable")
install.packages("plyr")
# install klippy for copy-to-clipboard button in code chunks
install.packages("remotes")
remotes::install_github("rlesur/klippy")Now that we have installed the packages, we activate them as shown below.
# set options
options(stringsAsFactors = F) # no automatic data transformation
options("scipen" = 100, "digits" = 12) # suppress math annotation
# activate packages
library(quanteda)
library(gutenbergr)
library(tidyverse)
library(flextable)
# activate klippy for copy-to-clipboard button
klippy::klippy()Once you have initiated the session by executing the code shown above, you are good to go.
6.1 Loading and processing textual data
For this tutorial, we will use Charles Darwin’s On the Origin of Species by means of Natural Selection which we download from the Project Gutenberg archive (see Stroube 2003). Thus, Darwin’s Origin of Species forms the basis of our analysis. You can use the code below to download this text into R (but you have to have access to the internet to do so).
origin <- gutenberg_works(
# define id of darwin's origin in project gutenberg
gutenberg_id == "1228") %>%
# download text
gutenberg_download(meta_fields = "gutenberg_id",
mirror = "http://mirrors.xmission.com/gutenberg/") %>%
# remove empty rows
dplyr::filter(text != "")gutenberg_id | text |
1,228 | Click on any of the filenumbers below to quickly view each ebook. |
1,228 | 1228 1859, First Edition |
1,228 | 22764 1860, Second Edition |
1,228 | 2009 1872, Sixth Edition, considered the definitive edition. |
1,228 | On |
1,228 | the Origin of Species |
1,228 | BY MEANS OF NATURAL SELECTION, |
1,228 | OR THE |
1,228 | PRESERVATION OF FAVOURED RACES IN THE STRUGGLE FOR LIFE. |
1,228 | By Charles Darwin, M.A., |
The table above shows that Darwin’s Origin of Species requires formatting so that we can use it. Therefore, we collapse it into a single object (or text) and remove superfluous white spaces.
origin <- origin$text %>%
# collapse lines into a single text
paste0(collapse = " ") %>%
# remove superfluous white spaces
str_squish(). |
Click on any of the filenumbers below to quickly view each ebook. 1228 1859, First Edition 22764 1860, Second Edition 2009 1872, Sixth Edition, considered the definitive edition. On the Origin of Species BY MEANS OF NATURAL SELECTION, OR THE PRESERVATION OF FAVOURED RACES IN THE STRUGGLE FOR LIFE. By Charles Darwin, M.A., Fellow Of The Royal, Geological, Linnæan, Etc., Societies; Author Of ‘Journal Of Researches During H.M.S. Beagle’s Voyage Round The World.’ LONDON: JOHN MURRAY, ALBEMARLE STREET. 1859. “But with regard to the material world, we can at least go so far as this—we can perceive that events are brought about not by insulated interpositions of Divine power, exerted in each particular case, but by the establishment of general laws.” W. WHEWELL: _Bridgewater Treatise_. “To conclude, therefore, let no man out of a weak conceit of sobriety, or an ill-applied moderation, think or maintain, that a man can search too far or be too well studied in the book of God’s word, or in the |
The result confirms that the entire text is now combined into a single character object.
6.2 Creating simple concordances
Now that we have loaded the data, we can easily extract concordances using the kwic function from the quanteda package. The kwic function takes the text (x) and the search pattern (pattern) as it main arguments but it also allows the specification of the context window, i.e. how many words/elements are show to the left and right of the key word (we will go over this later on).
kwic_natural <- kwic(
# define text
origin,
# define search pattern
pattern = "selection")
# inspect data
kwic_natural %>%
as.data.frame() %>%
head(10)## docname from to pre keyword
## 1 text1 44 44 Species BY MEANS OF NATURAL SELECTION
## 2 text1 275 275 EXISTENCE . 4 . NATURAL SELECTION
## 3 text1 411 411 and Origin . Principle of Selection
## 4 text1 421 421 Effects . Methodical and Unconscious Selection
## 5 text1 436 436 favourable to Man's power of Selection
## 6 text1 522 522 EXISTENCE . Bears on natural selection
## 7 text1 616 616 . CHAPTER 4 . NATURAL SELECTION
## 8 text1 619 619 . NATURAL SELECTION . Natural Selection
## 9 text1 626 626 its power compared with man's selection
## 10 text1 647 647 on both sexes . Sexual Selection
## post pattern
## 1 , OR THE PRESERVATION OF selection
## 2 . 5 . LAWS OF selection
## 3 anciently followed , its Effects selection
## 4 . Unknown Origin of our selection
## 5 . CHAPTER 2 . VARIATION selection
## 6 . The term used in selection
## 7 . Natural Selection : its selection
## 8 : its power compared with selection
## 9 , its power on characters selection
## 10 . On the generality of selectionYou will see that you get a warning stating that you should use token f?before extracting concordances. This can be done as shown below. Also, we can specify the package from which we want to use a function by adding the package name plus :: before the function (see below)
kwic_natural <- quanteda::kwic(
# define and tokenize text
quanteda::tokens(origin),
# define search pattern
pattern = "selection")docname | from | to | pre | keyword | post | pattern |
text1 | 44 | 44 | Species BY MEANS OF NATURAL | SELECTION | , OR THE PRESERVATION OF | selection |
text1 | 275 | 275 | EXISTENCE . 4 . NATURAL | SELECTION | . 5 . LAWS OF | selection |
text1 | 411 | 411 | and Origin . Principle of | Selection | anciently followed , its Effects | selection |
text1 | 421 | 421 | Effects . Methodical and Unconscious | Selection | . Unknown Origin of our | selection |
text1 | 436 | 436 | favourable to Man's power of | Selection | . CHAPTER 2 . VARIATION | selection |
text1 | 522 | 522 | EXISTENCE . Bears on natural | selection | . The term used in | selection |
text1 | 616 | 616 | . CHAPTER 4 . NATURAL | SELECTION | . Natural Selection : its | selection |
text1 | 619 | 619 | . NATURAL SELECTION . Natural | Selection | : its power compared with | selection |
text1 | 626 | 626 | its power compared with man's | selection | , its power on characters | selection |
text1 | 647 | 647 | on both sexes . Sexual | Selection | . On the generality of | selection |
We can easily extract the frequency of the search term (selection) using the nrow or the length functions which provide the number of rows of a tables (nrow) or the length of a vector (length).
nrow(kwic_natural)## [1] 412length(kwic_natural$keyword)## [1] 412The results show that there are 414 instances of the search term (selection) but we can also find out how often different variants (lower case versus upper case) of the search term were found using the table function. This is especially useful when searches involve many different search terms (while it is, admittedly, less useful in the present example).
table(kwic_natural$keyword)##
## selection Selection SELECTION
## 369 39 4To get a better understanding of the use of a word, it is often useful to extract more context. This is easily done by increasing size of the context window. To do this, we specify the window argument of the kwic function. In the example below, we set the context window size to 10 words/elements rather than using the default (which is 5 word/elements).
kwic_natural_longer <- kwic(
# define text
origin,
# define search pattern
pattern = "selection",
# define context window size
window = 10)docname | from | to | pre | keyword | post | pattern |
text1 | 44 | 44 | . On the Origin of Species BY MEANS OF NATURAL | SELECTION | , OR THE PRESERVATION OF FAVOURED RACES IN THE STRUGGLE | selection |
text1 | 275 | 275 | . 3 . STRUGGLE FOR EXISTENCE . 4 . NATURAL | SELECTION | . 5 . LAWS OF VARIATION . 6 . DIFFICULTIES | selection |
text1 | 411 | 411 | Domestic Pigeons , their Differences and Origin . Principle of | Selection | anciently followed , its Effects . Methodical and Unconscious Selection | selection |
text1 | 421 | 421 | Selection anciently followed , its Effects . Methodical and Unconscious | Selection | . Unknown Origin of our Domestic Productions . Circumstances favourable | selection |
text1 | 436 | 436 | our Domestic Productions . Circumstances favourable to Man's power of | Selection | . CHAPTER 2 . VARIATION UNDER NATURE . Variability . | selection |
text1 | 522 | 522 | CHAPTER 3 . STRUGGLE FOR EXISTENCE . Bears on natural | selection | . The term used in a wide sense . Geometrical | selection |
text1 | 616 | 616 | most important of all relations . CHAPTER 4 . NATURAL | SELECTION | . Natural Selection : its power compared with man's selection | selection |
text1 | 619 | 619 | all relations . CHAPTER 4 . NATURAL SELECTION . Natural | Selection | : its power compared with man's selection , its power | selection |
text1 | 626 | 626 | SELECTION . Natural Selection : its power compared with man's | selection | , its power on characters of trifling importance , its | selection |
text1 | 647 | 647 | power at all ages and on both sexes . Sexual | Selection | . On the generality of intercrosses between individuals of the | selection |
EXERCISE TIME!
`
- Extract the first 10 concordances for the word nature.
Answer
kwic_nature <- kwic(x = origin, pattern = "nature") ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_natural %>%
as.data.frame() %>%
head(10) ## docname from to pre keyword
## 1 text1 44 44 Species BY MEANS OF NATURAL SELECTION
## 2 text1 275 275 EXISTENCE . 4 . NATURAL SELECTION
## 3 text1 411 411 and Origin . Principle of Selection
## 4 text1 421 421 Effects . Methodical and Unconscious Selection
## 5 text1 436 436 favourable to Man's power of Selection
## 6 text1 522 522 EXISTENCE . Bears on natural selection
## 7 text1 616 616 . CHAPTER 4 . NATURAL SELECTION
## 8 text1 619 619 . NATURAL SELECTION . Natural Selection
## 9 text1 626 626 its power compared with man's selection
## 10 text1 647 647 on both sexes . Sexual Selection
## post pattern
## 1 , OR THE PRESERVATION OF selection
## 2 . 5 . LAWS OF selection
## 3 anciently followed , its Effects selection
## 4 . Unknown Origin of our selection
## 5 . CHAPTER 2 . VARIATION selection
## 6 . The term used in selection
## 7 . Natural Selection : its selection
## 8 : its power compared with selection
## 9 , its power on characters selection
## 10 . On the generality of selection- How many instances are there of the word nature?
Answer
kwic_nature %>%
as.data.frame() %>%
nrow() ## [1] 261- Extract concordances for the word origin and show the first 5 concordance lines.
Answer
kwic_origin <- kwic(x = origin, pattern = "origin") ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_origin %>%
as.data.frame() %>%
head(5) ## docname from to pre keyword
## 1 text1 37 37 definitive edition . On the Origin
## 2 text1 351 351 DETEAILED CONTENTS . ON THE ORIGIN
## 3 text1 391 391 between Varieties and Species . Origin
## 4 text1 407 407 Pigeons , their Differences and Origin
## 5 text1 424 424 and Unconscious Selection . Unknown Origin
## post pattern
## 1 of Species BY MEANS OF origin
## 2 OF SPECIES . INTRODUCTION . origin
## 3 of Domestic Varieties from one origin
## 4 . Principle of Selection anciently origin
## 5 of our Domestic Productions . origin`
6.3 Extracting more than single words
While extracting single words is very common, you may want to extract more than just one word. To extract phrases, all you need to so is to specify that the pattern you are looking for is a phrase, as shown below.
kwic_naturalselection <- kwic(origin, pattern = phrase("natural selection"))docname | from | to | pre | keyword | post | pattern |
text1 | 43 | 44 | of Species BY MEANS OF | NATURAL SELECTION | , OR THE PRESERVATION OF | natural selection |
text1 | 274 | 275 | FOR EXISTENCE . 4 . | NATURAL SELECTION | . 5 . LAWS OF | natural selection |
text1 | 521 | 522 | FOR EXISTENCE . Bears on | natural selection | . The term used in | natural selection |
text1 | 615 | 616 | relations . CHAPTER 4 . | NATURAL SELECTION | . Natural Selection : its | natural selection |
text1 | 618 | 619 | 4 . NATURAL SELECTION . | Natural Selection | : its power compared with | natural selection |
text1 | 666 | 667 | Circumstances favourable and unfavourable to | Natural Selection | , namely , intercrossing , | natural selection |
text1 | 685 | 686 | action . Extinction caused by | Natural Selection | . Divergence of Character , | natural selection |
text1 | 709 | 710 | to naturalisation . Action of | Natural Selection | , through Divergence of Character | natural selection |
text1 | 753 | 754 | and disuse , combined with | natural selection | ; organs of flight and | natural selection |
text1 | 925 | 926 | embraced by the theory of | Natural Selection | . CHAPTER 7 . INSTINCT | natural selection |
Of course you can extend this to longer sequences such as entire sentences. However, you may want to extract more or less concrete patterns rather than words or phrases. To search for patterns rather than words, you need to include regular expressions in your search pattern.
EXERCISE TIME!
`
- Extract the first 10 concordances for the phrase natural habitat.
Answer
kwic_naturalhabitat <- kwic(x = origin, pattern = phrase("natural habitat")) ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_naturalhabitat %>%
as.data.frame() %>%
head(10) ## [1] docname from to pre keyword post pattern
## <0 Zeilen> (oder row.names mit Länge 0)- How many instances are there of the phrase natural habitat?
Answer
kwic_naturalhabitat %>%
as.data.frame() %>%
nrow() ## [1] 0- Extract concordances for the phrase the origin and show the first 5 concordance lines.
Answer
kwic_theorigin <- kwic(x = origin, pattern = phrase("the origin")) ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_theorigin %>%
as.data.frame() %>%
head(5) ## docname from to pre keyword
## 1 text1 36 37 the definitive edition . On the Origin
## 2 text1 350 351 INDEX DETEAILED CONTENTS . ON THE ORIGIN
## 3 text1 1617 1618 . Concluding remarks . ON THE ORIGIN
## 4 text1 1679 1680 to throw some light on the origin
## 5 text1 1910 1911 conclusions that I have on the origin
## post pattern
## 1 of Species BY MEANS OF the origin
## 2 OF SPECIES . INTRODUCTION . the origin
## 3 OF SPECIES . INTRODUCTION . the origin
## 4 of species - that mystery the origin
## 5 of species . Last year the origin`
6.4 Searches using regular expressions
Regular expressions allow you to search for abstract patterns rather than concrete words or phrases which provides you with an extreme flexibility in what you can retrieve. A regular expression (in short also called regex or regexp) is a special sequence of characters that stand for are that describe a pattern. You can think of regular expressions as very powerful combinations of wildcards or as wildcards on steroids. For example, the sequence [a-z]{1,3} is a regular expression that stands for one up to three lower case characters and if you searched for this regular expression, you would get, for instance, is, a, an, of, the, my, our, etc, and many other short words as results.
There are three basic types of regular expressions:
regular expressions that stand for individual symbols and determine frequencies
regular expressions that stand for classes of symbols
regular expressions that stand for structural properties
The regular expressions below show the first type of regular expressions, i.e. regular expressions that stand for individual symbols and determine frequencies.
RegEx Symbol/Sequence | Explanation | Example |
? | The preceding item is optional and will be matched at most once | walk[a-z]? = walk, walks |
* | The preceding item will be matched zero or more times | walk[a-z]* = walk, walks, walked, walking |
+ | The preceding item will be matched one or more times | walk[a-z]+ = walks, walked, walking |
{n} | The preceding item is matched exactly n times | walk[a-z]{2} = walked |
{n,} | The preceding item is matched n or more times | walk[a-z]{2,} = walked, walking |
{n,m} | The preceding item is matched at least n times, but not more than m times | walk[a-z]{2,3} = walked, walking |
The regular expressions below show the second type of regular expressions, i.e. regular expressions that stand for classes of symbols.
RegEx Symbol/Sequence | Explanation |
[ab] | lower case a and b |
[AB] | upper case a and b |
[12] | digits 1 and 2 |
[:digit:] | digits: 0 1 2 3 4 5 6 7 8 9 |
[:lower:] | lower case characters: a?z |
[:upper:] | upper case characters: A?Z |
[:alpha:] | alphabetic characters: a?z and A?Z |
[:alnum:] | digits and alphabetic characters |
[:punct:] | punctuation characters: . , ; etc. |
[:graph:] | graphical characters: [:alnum:] and [:punct:] |
[:blank:] | blank characters: Space and tab |
[:space:] | space characters: Space, tab, newline, and other space characters |
[:print:] | printable characters: [:alnum:], [:punct:] and [:space:] |
The regular expressions that denote classes of symbols are enclosed in [] and :. The last type of regular expressions, i.e. regular expressions that stand for structural properties are shown below.
RegEx Symbol/Sequence | Explanation |
\\w | Word characters: [[:alnum:]_] |
\\W | No word characters: [^[:alnum:]_] |
\\s | Space characters: [[:blank:]] |
\\S | No space characters: [^[:blank:]] |
\\d | Digits: [[:digit:]] |
\\D | No digits: [^[:digit:]] |
\\b | Word edge |
\\B | No word edge |
< | Word beginning |
> | Word end |
^ | Beginning of a string |
$ | End of a string |
To include regular expressions in your KWIC searches, you include them in your search pattern and set the argument valuetype to "regex". The search pattern "\\bnatu.*|\\bselec.*" retrieves elements that contain natu and selec followed by any characters and where the n in natu and the s in selec are at a word boundary, i.e. where they are the first letters of a word. Hence, our search would not retrieve words like unnatural or deselect. The | is an operator (like +, -, or *) that stands for or.
# define search patterns
patterns <- c("\\bnatu.*|\\bselec.*")
kwic_regex <- kwic(
# define text
origin,
# define search pattern
patterns,
# define valuetype
valuetype = "regex")docname | from | to | pre | keyword | post | pattern |
text1 | 43 | 43 | of Species BY MEANS OF | NATURAL | SELECTION , OR THE PRESERVATION | \bnatu.*|\bselec.* |
text1 | 44 | 44 | Species BY MEANS OF NATURAL | SELECTION | , OR THE PRESERVATION OF | \bnatu.*|\bselec.* |
text1 | 264 | 264 | . 2 . VARIATION UNDER | NATURE | . 3 . STRUGGLE FOR | \bnatu.*|\bselec.* |
text1 | 274 | 274 | FOR EXISTENCE . 4 . | NATURAL | SELECTION . 5 . LAWS | \bnatu.*|\bselec.* |
text1 | 275 | 275 | EXISTENCE . 4 . NATURAL | SELECTION | . 5 . LAWS OF | \bnatu.*|\bselec.* |
text1 | 411 | 411 | and Origin . Principle of | Selection | anciently followed , its Effects | \bnatu.*|\bselec.* |
text1 | 421 | 421 | Effects . Methodical and Unconscious | Selection | . Unknown Origin of our | \bnatu.*|\bselec.* |
text1 | 436 | 436 | favourable to Man's power of | Selection | . CHAPTER 2 . VARIATION | \bnatu.*|\bselec.* |
text1 | 443 | 443 | CHAPTER 2 . VARIATION UNDER | NATURE | . Variability . Individual Differences | \bnatu.*|\bselec.* |
text1 | 521 | 521 | FOR EXISTENCE . Bears on | natural | selection . The term used | \bnatu.*|\bselec.* |
EXERCISE TIME!
`
- Extract the first 10 concordances for words containing exu.
Answer
kwic_exu <- kwic(x = origin, pattern = ".*exu.*", valuetype = "regex") ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_exu %>%
as.data.frame() %>%
head(10) ## docname from to pre keyword
## 1 text1 646 646 and on both sexes . Sexual
## 2 text1 806 806 variable than generic : secondary sexual
## 3 text1 29294 29294 and on both sexes . Sexual
## 4 text1 31953 31953 like every other structure . _Sexual
## 5 text1 32040 32040 words on what I call Sexual
## 6 text1 32082 32082 few or no offspring . Sexual
## 7 text1 32157 32157 chance of leaving offspring . Sexual
## 8 text1 32330 32330 be given through means of sexual
## 9 text1 32628 32628 having been chiefly modified by sexual
## 10 text1 32726 32726 have been mainly caused by sexual
## post pattern
## 1 Selection . On the generality .*exu.*
## 2 characters variable . Species of .*exu.*
## 3 Selection . On the generality .*exu.*
## 4 Selection_ . - Inasmuch as .*exu.*
## 5 Selection . This depends , .*exu.*
## 6 selection is , therefore , .*exu.*
## 7 selection by always allowing the .*exu.*
## 8 selection , as the mane .*exu.*
## 9 selection , acting when the .*exu.*
## 10 selection ; that is , .*exu.*- How many instances are there of words beginning with nonet?
Answer
kwic_nonet <- kwic(x = origin, pattern = "\\bnonet.*", valuetype = "regex") %>%
as.data.frame() %>%
nrow() ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first.- Extract concordances for words ending with ption and show the first 5 concordance lines.
Answer
kwic_ption <- kwic(x = origin, pattern = "ption\\b", valuetype = "regex") ## Warning: 'kwic.character()' is deprecated. Use 'tokens()' first. # inspect
kwic_ption %>%
as.data.frame() %>%
head(5) ## docname from to pre keyword
## 1 text1 1605 1605 extended . Effects of its adoption
## 2 text1 2641 2641 see them ; but this assumption
## 3 text1 3926 3926 or at the instant of conception
## 4 text1 3990 3990 prior to the act of conception
## 5 text1 4233 4233 under confinement , with the exception
## post pattern
## 1 on the study of Natural ption\\b
## 2 seems to me to be ption\\b
## 3 . Geoffroy St . Hilaire's ption\\b
## 4 . Several reasons make me ption\\b
## 5 of the plantigrades or bear ption\\b`
6.5 Piping concordances
Quite often, we only want to retrieve patterns if they occur in a certain context. For instance, we might be interested in instances of selection but only if the preceding word is natural. Such conditional concordances could be extracted using regular expressions but they are easier to retrieve by piping. Piping is done using the %>% function from the dplyr package and the piping sequence can be translated as and then. We can then filter those concordances that contain natural using the filter function from the dplyr package. Note the the $ stands for the end of a string so that natural$ means that natural is the last element in the string that is preceding the keyword.
kwic_pipe <- kwic(x = origin, pattern = "selection") %>%
dplyr::filter(stringr::str_detect(pre, "natural$|NATURAL$"))docname | from | to | pre | keyword | post | pattern |
text1 | 44 | 44 | Species BY MEANS OF NATURAL | SELECTION | , OR THE PRESERVATION OF | selection |
text1 | 275 | 275 | EXISTENCE . 4 . NATURAL | SELECTION | . 5 . LAWS OF | selection |
text1 | 522 | 522 | EXISTENCE . Bears on natural | selection | . The term used in | selection |
text1 | 616 | 616 | . CHAPTER 4 . NATURAL | SELECTION | . Natural Selection : its | selection |
text1 | 754 | 754 | disuse , combined with natural | selection | ; organs of flight and | selection |
text1 | 1,597 | 1,597 | far the theory of natural | selection | may be extended . Effects | selection |
text1 | 6,617 | 6,617 | do occur ; but natural | selection | , as will hereafter be | selection |
text1 | 14,827 | 14,827 | a process of " natural | selection | , " as will hereafter | selection |
text1 | 17,269 | 17,269 | they afford materials for natural | selection | to accumulate , in the | selection |
text1 | 17,819 | 17,819 | and rendered definite by natural | selection | , as hereafter will be | selection |
Piping is a very useful helper function and it is very frequently used in R - not only in the context of text processing but in all data science related domains.
6.6 Arranging concordances and adding frequency information
When inspecting concordances, it is useful to re-order the concordances so that they do not appear in the order that they appeared in the text or texts but by the context. To reorder concordances, we can use the arrange function from the dplyr package which takes the column according to which we want to re-arrange the data as it main argument.
In the example below, we extract all instances of natural and then arrange the instances according to the content of the post column in alphabetical.
kwic_ordered <- kwic(x = origin, pattern = "natural") %>%
dplyr::arrange(post)docname | from | to | pre | keyword | post | pattern |
text1 | 176,207 | 176,207 | , 190 . System , | natural | , 413 . Tail : | natural |
text1 | 176,668 | 176,668 | , 159 . Varieties : | natural | , 44 . struggle between | natural |
text1 | 175,731 | 175,731 | . unconscious , 34 . | natural | , 80 . sexual , | natural |
text1 | 147,280 | 147,280 | and this would be strictly | natural | , as it would connect | natural |
text1 | 175,739 | 175,739 | . sexual , 87 . | natural | , circumstances favourable to , | natural |
text1 | 146,387 | 146,387 | genealogical in order to be | natural | ; but that the _amount_ | natural |
text1 | 111,947 | 111,947 | of old forms , both | natural | and artificial , are bound | natural |
text1 | 56,947 | 56,947 | parts having been accumulated by | natural | and sexual selection , and | natural |
text1 | 56,630 | 56,630 | be taken advantage of by | natural | and sexual selection , in | natural |
text1 | 150,464 | 150,464 | , or at least a | natural | arrangement , would be possible | natural |
Arranging concordances according to alphabetical properties may, however, not be the most useful option. A more useful option may be to arrange concordances according to the frequency of co-occurring terms or collocates. In order to do this, we need to extract the co-occurring words and calculate their frequency. We can do this by combining the mutate, group_by, n() functions from the dplyr package with the str_remove_all function from the stringr package. Then, we arrange the concordances by the frequency of the collocates in descending order (that is why we put a - in the arrange function). In order to do this, we need to
create a new variable or column which represents the word that co-occurs with, or, as in the example below, immediately follows the search term. In the example below, we use the
mutatefunction to create a new column calledpost_word. We then use thestr_remove_allfunction to remove everything except for the word that immediately follows the search term (we simply remove everything and including a white space).group the data by the word that immediately follows the search term.
create a new column called
post_word_freqwhich represents the frequencies of all the words that immediately follow the search term.arrange the concordances by the frequency of the collocates in descending order.
kwic_ordered_coll <- kwic(
# define text
x = origin,
# define search pattern
pattern = "natural") %>%
# extract word following the keyword
dplyr::mutate(post_word = str_remove_all(post, " .*")) %>%
# group following words
dplyr::group_by(post_word) %>%
# extract frequencies of the following words
dplyr::mutate(post_word_freq = n()) %>%
# arrange/order by the frequency of the following word
dplyr::arrange(-post_word_freq)docname | from | to | pre | keyword | post | pattern | post_word | post_word_freq |
text1 | 618 | 618 | 4 . NATURAL SELECTION . | Natural | Selection : its power compared | natural | Selection | 4 |
text1 | 666 | 666 | Circumstances favourable and unfavourable to | Natural | Selection , namely , intercrossing | natural | Selection | 4 |
text1 | 685 | 685 | action . Extinction caused by | Natural | Selection . Divergence of Character | natural | Selection | 4 |
text1 | 709 | 709 | to naturalisation . Action of | Natural | Selection , through Divergence of | natural | Selection | 4 |
text1 | 43 | 43 | of Species BY MEANS OF | NATURAL | SELECTION , OR THE PRESERVATION | natural | SELECTION | 3 |
text1 | 274 | 274 | FOR EXISTENCE . 4 . | NATURAL | SELECTION . 5 . LAWS | natural | SELECTION | 3 |
text1 | 615 | 615 | relations . CHAPTER 4 . | NATURAL | SELECTION . Natural Selection : | natural | SELECTION | 3 |
text1 | 521 | 521 | FOR EXISTENCE . Bears on | natural | selection . The term used | natural | selection | 1 |
We add more columns according to which we could arrange the concordance following the same schema. For example, we could add another column that represented the frequency of words that immediately preceded the search term and then arrange according to this column.
6.7 Ordering by subsequent elements
In this section, we will extract the three words following the keyword (selection) and organize the concordances by the frequencies of the following words. We begin by inspecting the first 6 lines of the concordance of selection.
head(kwic_natural)## Keyword-in-context with 6 matches.
## [text1, 44] Species BY MEANS OF NATURAL | SELECTION |
## [text1, 275] EXISTENCE. 4. NATURAL | SELECTION |
## [text1, 411] and Origin. Principle of | Selection |
## [text1, 421] Effects. Methodical and Unconscious | Selection |
## [text1, 436] favourable to Man's power of | Selection |
## [text1, 522] EXISTENCE. Bears on natural | selection |
##
## , OR THE PRESERVATION OF
## . 5. LAWS OF
## anciently followed, its Effects
## . Unknown Origin of our
## . CHAPTER 2. VARIATION
## . The term used inNext, we take the concordances and create a clean post column that is all in lower case and that does not contain any punctuation.
kwic_natural %>%
# convert to data frame
as.data.frame() %>%
# create new CleanPost
dplyr::mutate(CleanPost = stringr::str_remove_all(post, "[:punct:]"),
CleanPost = stringr::str_squish(CleanPost),
CleanPost = tolower(CleanPost))-> kwic_natural_following
# inspect
head(kwic_natural_following)## docname from to pre keyword
## 1 text1 44 44 Species BY MEANS OF NATURAL SELECTION
## 2 text1 275 275 EXISTENCE . 4 . NATURAL SELECTION
## 3 text1 411 411 and Origin . Principle of Selection
## 4 text1 421 421 Effects . Methodical and Unconscious Selection
## 5 text1 436 436 favourable to Man's power of Selection
## 6 text1 522 522 EXISTENCE . Bears on natural selection
## post pattern CleanPost
## 1 , OR THE PRESERVATION OF selection or the preservation of
## 2 . 5 . LAWS OF selection 5 laws of
## 3 anciently followed , its Effects selection anciently followed its effects
## 4 . Unknown Origin of our selection unknown origin of our
## 5 . CHAPTER 2 . VARIATION selection chapter 2 variation
## 6 . The term used in selection the term used inIn a next step, we extract the 1st, 2nd, and 3rd words following the keyword.
kwic_natural_following %>%
# extract first element after keyword
dplyr::mutate(FirstWord = stringr::str_remove_all(CleanPost, " .*")) %>%
# extract second element after keyword
dplyr::mutate(SecWord = stringr::str_remove(CleanPost, ".*? "),
SecWord = stringr::str_remove_all(SecWord, " .*")) %>%
# extract third element after keyword
dplyr::mutate(ThirdWord = stringr::str_remove(CleanPost, ".*? "),
ThirdWord = stringr::str_remove(ThirdWord, ".*? "),
ThirdWord = stringr::str_remove_all(ThirdWord, " .*")) -> kwic_natural_following
# inspect
head(kwic_natural_following)## docname from to pre keyword
## 1 text1 44 44 Species BY MEANS OF NATURAL SELECTION
## 2 text1 275 275 EXISTENCE . 4 . NATURAL SELECTION
## 3 text1 411 411 and Origin . Principle of Selection
## 4 text1 421 421 Effects . Methodical and Unconscious Selection
## 5 text1 436 436 favourable to Man's power of Selection
## 6 text1 522 522 EXISTENCE . Bears on natural selection
## post pattern CleanPost
## 1 , OR THE PRESERVATION OF selection or the preservation of
## 2 . 5 . LAWS OF selection 5 laws of
## 3 anciently followed , its Effects selection anciently followed its effects
## 4 . Unknown Origin of our selection unknown origin of our
## 5 . CHAPTER 2 . VARIATION selection chapter 2 variation
## 6 . The term used in selection the term used in
## FirstWord SecWord ThirdWord
## 1 or the preservation
## 2 5 laws of
## 3 anciently followed its
## 4 unknown origin of
## 5 chapter 2 variation
## 6 the term usedNext, we calculate the frequencies of the subsequent words and order in descending order from the 1st to the 3rd word following the keyword.
kwic_natural_following %>%
# calculate frequency of following words
# 1st word
dplyr::group_by(FirstWord) %>%
dplyr::mutate(FreqW1 = n()) %>%
# 2nd word
dplyr::group_by(SecWord) %>%
dplyr::mutate(FreqW2 = n()) %>%
# 3rd word
dplyr::group_by(ThirdWord) %>%
dplyr::mutate(FreqW3 = n()) %>%
# ungroup
dplyr::ungroup() %>%
# arrange by following words
dplyr::arrange(-FreqW1, -FreqW2, -FreqW3) -> kwic_natural_following
# inspect results
head(kwic_natural_following, 10)## # A tibble: 10 × 14
## docname from to pre keyword post pattern CleanPost FirstWord SecWord
## <chr> <int> <int> <chr> <chr> <chr> <fct> <chr> <chr> <chr>
## 1 text1 3064 3064 This f… Select… will… select… will be … will be
## 2 text1 31421 31421 state … select… will… select… will be … will be
## 3 text1 31988 31988 and if… select… will… select… will be … will be
## 4 text1 60694 60694 slow p… select… will… select… will in … will in
## 5 text1 15600 15600 called… select… will… select… will alw… will always
## 6 text1 37304 37304 as mig… select… will… select… will alw… will always
## 7 text1 72213 72213 becaus… select… will… select… will alw… will always
## 8 text1 39275 39275 new sp… select… will… select… will alw… will always
## 9 text1 39449 39449 I do b… select… will… select… will alw… will always
## 10 text1 43007 43007 modifi… select… will… select… will alw… will always
## # … with 4 more variables: ThirdWord <chr>, FreqW1 <int>, FreqW2 <int>,
## # FreqW3 <int>The results now show the concordance arranged by the frequency of the words following the keyword.