Week 1 What are Corpus Linguistics and Text Analysis?
This tutorial introduces Corpus Linguistics (see O’Keeffe and McCarthy 2022; S. Th. Gries 2009; Biber, Conrad, and Reppen 1998; S. T. Gries 2009), i.e., the study of language through the analysis of large collections of text (corpora), and Text Analysis (see Bernard and Ryan 1998; Kabanoff 1997; Popping 2000), i.e. computer-based analysis of language data or the (semi-)automated extraction of information from text.
Corpus linguistics is a research methodology that involves the systematic analysis of large collections of natural language data, known as corpora. Corpus linguistics is based on the idea that language can be best understood by analyzing large, representative samples of naturally occurring language use. Corpora can be compiled from a variety of sources, including written texts, spoken language, and even online communication. Through the use of computational tools and statistical methods, corpus linguistics enables researchers to identify patterns and relationships within language use, providing insights into linguistic phenomena such as grammar, vocabulary, and discourse.
Text Analysis is associated with a divers set of computational methods that enable researchers to explore text and analyse unstructured data, i.e., text (unstructured is used here in contrast to structured, i.e., tabular data). Due to the increasing availability of large amounts of textual data, text analytics methods and distant reading techniques are becoming more and more important and relevant to a larger body of researchers and disciplines.
This tutorial introduces basic concepts of Corpus Linguistics Text Analysis (also referred to as Distant Reading). The aim is not to provide a fully-fledged analysis but rather to discuss and explore selected useful methods associated with text analysis and distant reading.
What is the difference between corpus linguistics and text analysis?
Text analysis and corpus linguistics are related but distinct fields.
Text analysis is a broad term that refers to any systematic process of examining text, whether it be a single document or a collection of documents, in order to gain insights into its content, meaning, or other characteristics. Text analysis can involve various methods and techniques, such as content analysis, discourse analysis, and sentiment analysis.
Corpus linguistics, on the other hand, is a specific subfield of linguistics that uses large collections of texts, called corpora, as the basis for linguistic analysis. Corpus linguistics involves the use of computational tools and statistical methods to analyze linguistic patterns and relationships within a corpus.
While both text analysis and corpus linguistics involve the systematic examination of texts, corpus linguistics is more focused on the quantitative analysis of large, representative samples of language use, whereas text analysis can encompass a broader range of qualitative and quantitative methods for analyzing text.
Why use Corpus Linguistics (CL) or Text Analysis (TA)?
Since both CL and TA extract and analyse information from textual data, they can be considered a derivative of computational linguistics or an application of Natural Language Processing (NLP). As such, CL and TA represent the application of computational methods in the humanities and thus falls within computational humanities research.
The advantages of CL and TA include:
Extraction of information from large textual data sets
Replicability and reproducibility of analyses
What is relevant to consider here is that CL and TA contrasts with traditional armchair linguistics or close-reading techniques which do not employ computational means of exploring and analyzing texts. CL and TA, while allowing for qualitative analysis, builds upon quantitative information, i.e. information about frequencies or conditional probabilities.
Armchair linguistics refers to the analysis of language through introspection and it differs from CL in that CL uses (large) amounts of data to arrive at an understanding how language works.
Why is corpus linguistics becoming ever more popular in research focusin on language learning and teaching?
Corpus linguistics has become increasingly popular in language learning and teaching research for several reasons.
- Corpora provide a large and diverse set of authentic language data, which can be used to develop and evaluate language learning and teaching materials and methods. Corpus-based research can help identify patterns of language use, highlight common errors, and reveal areas of difficulty for language learners.
- Corpus linguistics offers a more systematic and objective way of analyzing language data than traditional approaches to language analysis. By using computational tools and statistical methods, researchers can identify patterns and relationships within language use that may not be immediately apparent through traditional methods of language analysis.
- Corpus linguistics can help bridge the gap between theory and practice in language learning and teaching. By providing empirical evidence of how language is actually used in real-world contexts, corpus-based research can inform language pedagogy and curriculum design, helping to ensure that language teaching is grounded in sound linguistic principles and is effective in helping learners achieve their language learning goals.
Overall, corpus linguistics has proven to be a valuable tool for language learning and teaching research, providing a rich and reliable source of data that can be used to improve language pedagogy and better understand how language is used in real-world contexts.
*Why is Ditant Reading becoming ever more popular in the humanities?**
Distant Reading is a cover term for applications of TA that allow to investigate literary and cultural trends by analyzing large amounts of textual data. close reading refers to reading texts in the traditional sense. Text Analysis and distant reading are similar with respect to the methods that are used but with different outlooks. The outlook of distant reading is to extract information from text without close reading, i.e. reading the document(s) itself but rather focusing on emerging patterns in the language that is used.
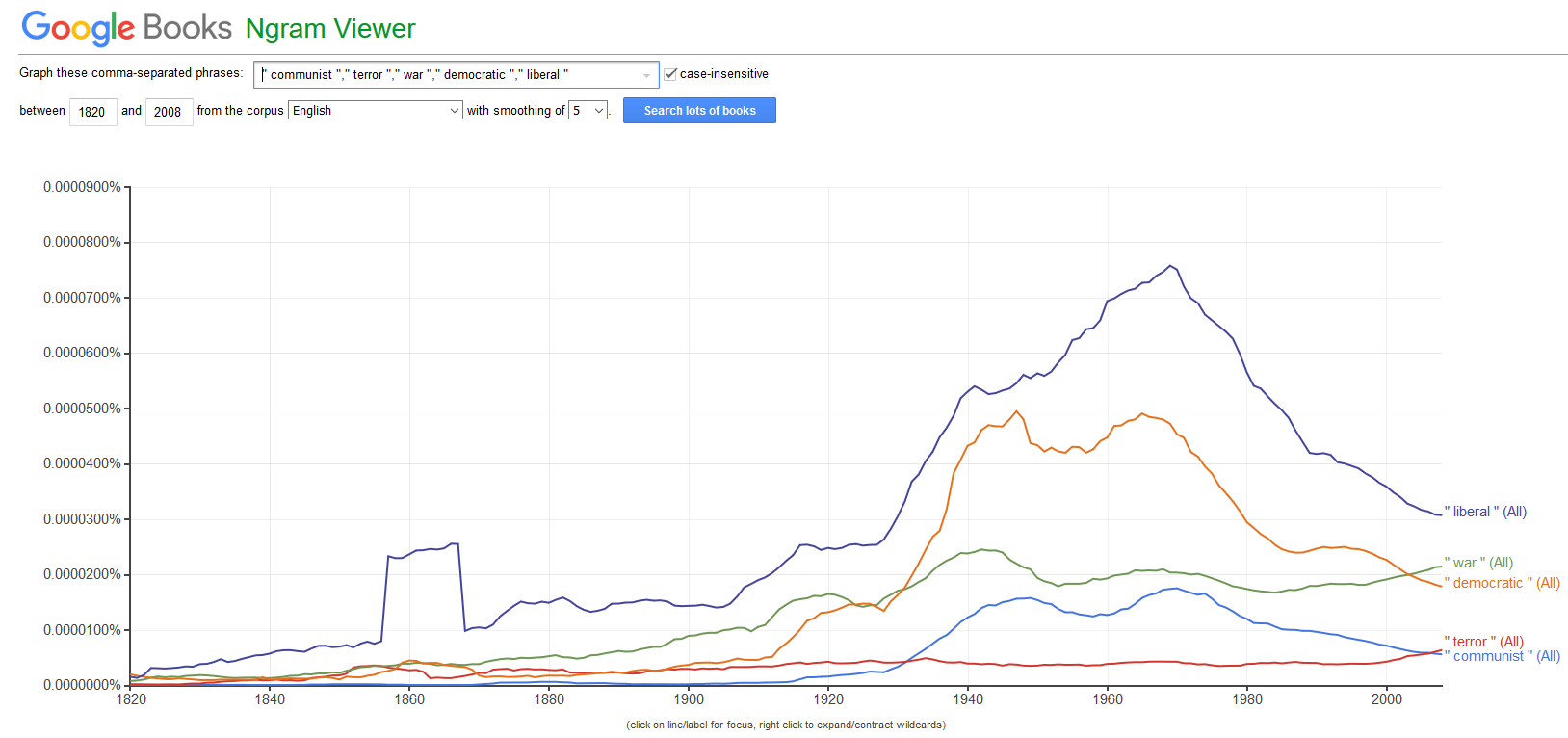
Text Analysis is rapidly gaining popularity in the humanities because textual data is readily available and because computational methods can be applied to a huge variety of research questions. The attractiveness of computational text analysis based on digitally available texts and in their capability to provide insights that cannot be derived from close reading techniques.
While there are some nuances, Text Mining, Text Analytics, and Distant Reading are more or less synonymous with Text Analysis. Regarding these minor differences, Text Analysis is commonly considered more qualitative while Text Analytics is considered to be quantitative. In contrast to Text Analysis, Text Mining is often more data-driven and usually applies methods without substantive supervision or assistance from the human researcher. Distant Reading is used mostly when dealing with literary or academic texts while Text Mining is associated with social media or more generally Big Data. In the following, we use Text Analysis as a cover term encompassing Text Mining, Text Analytics, and Distant Reading.
While rapidly growing as a valid approach to analyzing textual data, Text Analysis is critizised for lack of “quantitative rigor and because its findings are either banal or, if interesting, not statistically robust (see here. This criticism is correct in that most of the analysis that performed in Computational Literary Studies (CLS) are not yet as rigorous as analyses in fields that have a longer history of computational based, quantitative research, such as, for instance, corpus linguistics. However, the practices and methods used in CLS will be refined, adapted and show a rapid increase in quality if more research is devoted to these approaches. Text Analysis simply offers an alternative way to analyze texts that is not in competition to traditional techniques but rather complements them.
So far, most of the applications of Text Analysis are based upon a relatively limited number of key procedures or concepts (e.g. concordancing, word frequencies, annotation or tagging, parsing, collocation, text classification, Sentiment Analysis, Entity Extraction, Topic Modeling, etc.). In the following, we will explore these procedures and introduce some basic tools that help you perform the introduced tasks.
Basic Concepts in Corpus Linguistics and Text Analysis
This session introduces basic concepts in corpus linguistics and text analysis.
Glossary of Important Concepts
Below, you will find explanations of concepts and methods that are important in Text Analysis and also links to relevant resources (including LADAL tutorials).
Word
What a word is is actually very tricky. For instance, How many words are there in this sentence?
The cat sat on the mat One answer is that there are six words; that is, there are six groups of characters which are separated according to typographical convention. But there is another answer: There are five words, that is five distinct sequences of characters and one of those sequences (the) occurs twice. The terms commonly used to make this distinction are type and token. Tokens are instances of types, therefore if we count tokens, we count without considering repetition, while if we count types, we do consider repetition. In our example, there are five types (the, cat, sat, on, mat) but six tokens, because there are two tokens of one of the types (the).
There is a further distinction we may need to make which we can see if we consider another question: are cat and cats the same word? They are distinct types, and therefore must also be distinct as tokens. But we have an intuition that at some level they are related, that there is some more abstract item which underlies both of them. This concept is usually referred to as a lemma.
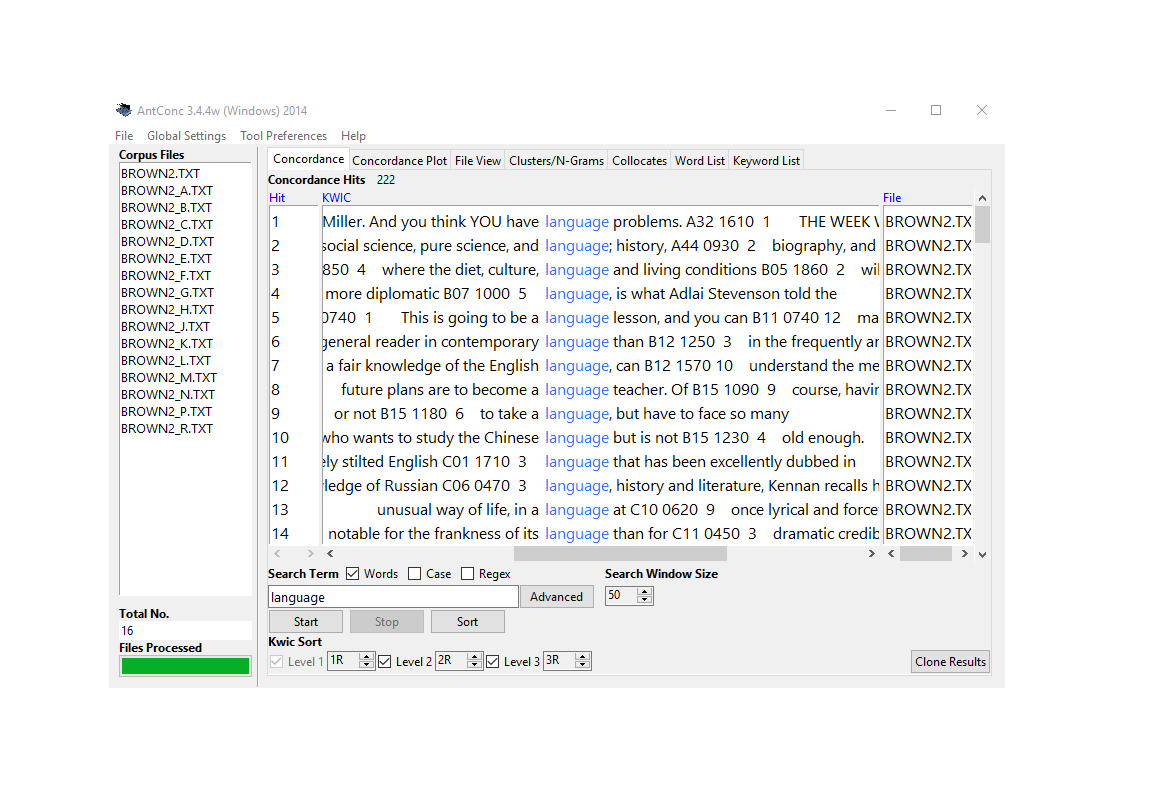
Concordancing
In Text Analysis, concordancing refers to the extraction of words from a given text or texts (Lindquist 2009). Commonly, concordances are displayed in the form of key-word in contexts (KWIC) where the search term is shown with some preceding and following context. Thus, such displays are referred to as key word in context concordances. A more elaborate tutorial on how to perform concordancing with R is available here. If you do not want to use coding to extract concordances, a highly recommendable tool for extracting concordances (and many other TA tasks) is AntConc.
Concordancing is helpful for seeing how the term is used in the data, for inspecting how often a given word occurs in a text or a collection of texts, for extracting examples, and it also represents a basic procedure and often the first step in more sophisticated analyses of language data.
Corpus (pl. Corpora)
A corpus is a machine readable and electronically stored collection of natural language texts representing writing or speech chosen to be characteristic of a variety or the state of a language (see sinclair1991corpus?). Corpora are great for extracting examples of natural examples and testing research hypotheses as it is easy to obtain information on frequencies, grammatical patterns, or collocations and they are commonly publicly available so the research results can be contrasted, compared and repeated.
There are four main types of corpora:
- Text corpora: These are collections of written texts that are used to study written language. Text corpora can include books, newspapers, magazines, and other written materials (e.g., the Corpus of Historical American English, COHA).
- Spoken corpora: These are collections of spoken language that are used to study oral language. Spoken corpora can include recordings of conversations, speeches, interviews, and other spoken interactions (e.g., the Australian Radio Talkback corpus).
- Parallel corpora: These are collections of texts or spoken language that are translated into multiple languages. Parallel corpora are used to study translation and language transfer (e.g., the Europarl Corpus).
- Multimodal corpora: These are collections of language data that include multiple modes of communication, such as spoken language, written language, images, and videos (e.g., British National Corpus, BNC).
- Diachronic corpora: These are collections of language data that span a long period of time. Diachronic corpora are used to study language change over time (e.g., the Penn-Helsinki Parsed Corpus of Early Modern English).
- Synchronic corpora: These are collections of language data that are collected at a particular point in time. Synchronic corpora are used to study language variation and language use in a particular community or context (e.g., the Corpus of Contemporary American English, COCA).
- Specialized corpora: These are collections of language data that focus on a particular domain or topic, such as medical language, legal language, or scientific language (e.g., the Child Language Data Exchange System, CHILDES).
- Online corpora: Online corpora are collections of language data that are available for access and search on the internet (e.g., the Corpus of Contemporary American English, COCA).
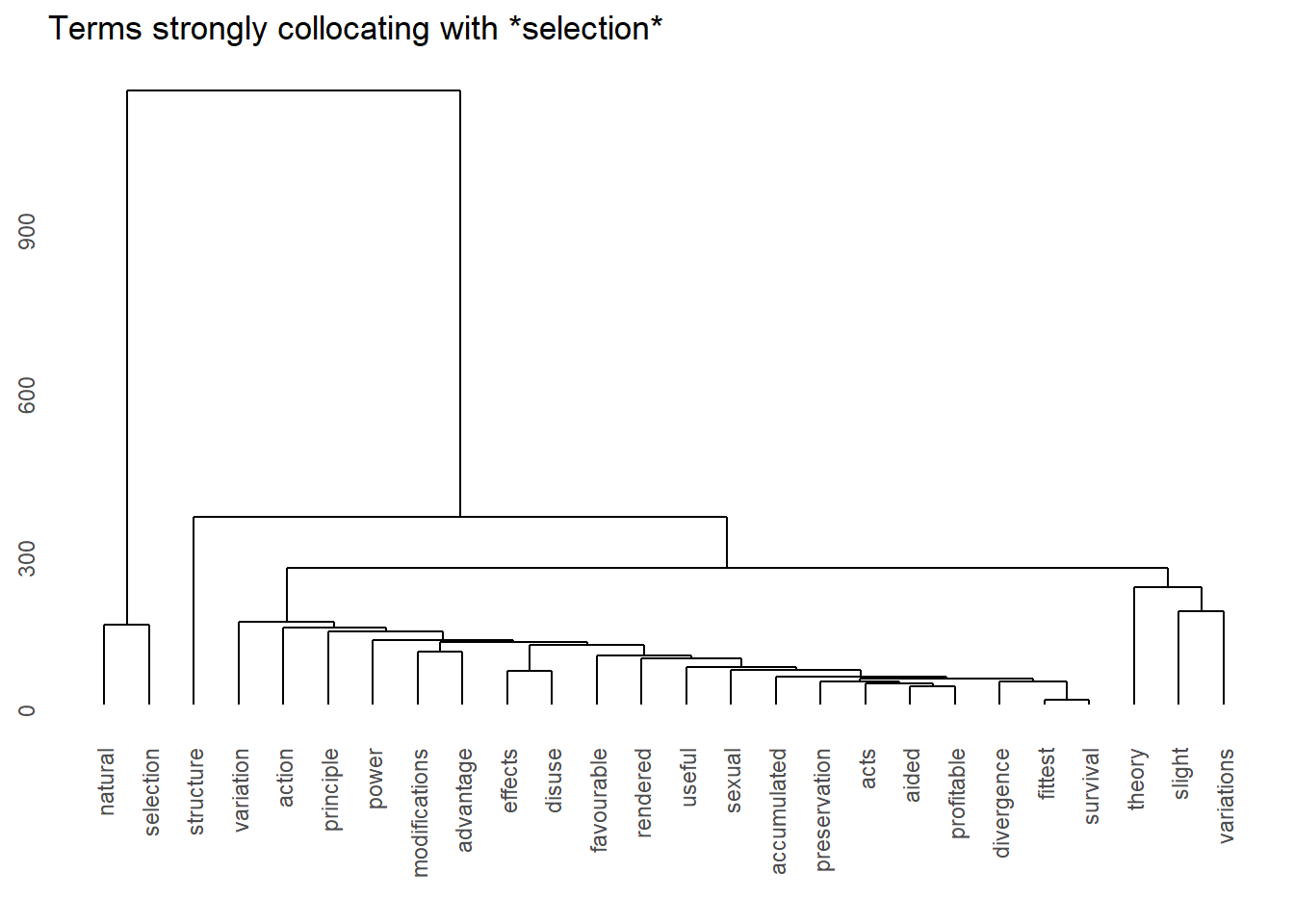
Collocations
Collocations are words that are attracted to each other (and that co-occur or co-locate together), e.g., Merry Christmas, Good Morning, No worries, or Fuck off. Collocations are important because any word in any given language has collocations, i.e., others words that are attracted to that word or words that that word is attracted to allow us to anticipate what word comes next and collocations are context/text type specific. It is important to note that collocations to not have to appear/occur right next to each other but that other words can be in between. There are various different statistical measures are used to define the strength of the collocations, like the Mutual Information (MI) score and log-likelihood (see here for an over view of different association strengths measures).
Document Classification
Document or Text Classification (also referred to as text categorization) generally refers to process of grouping texts or documents based on similarity. This similarity can be based on word frequencies or other linguistics features but also on text external features such as genre labels or polarity scores.
Document-Term Matrix
Document-Term Matrices (DTM) and Term- Document Matrices (TDM) contain the frequencies of words per document. DTM and TDM differ in whether the words or the documents are represented as rows. Thus, the words (terms) are listed as row names and the documents represent the column names while the matrix itself contains the frequencies of the words in the documents.
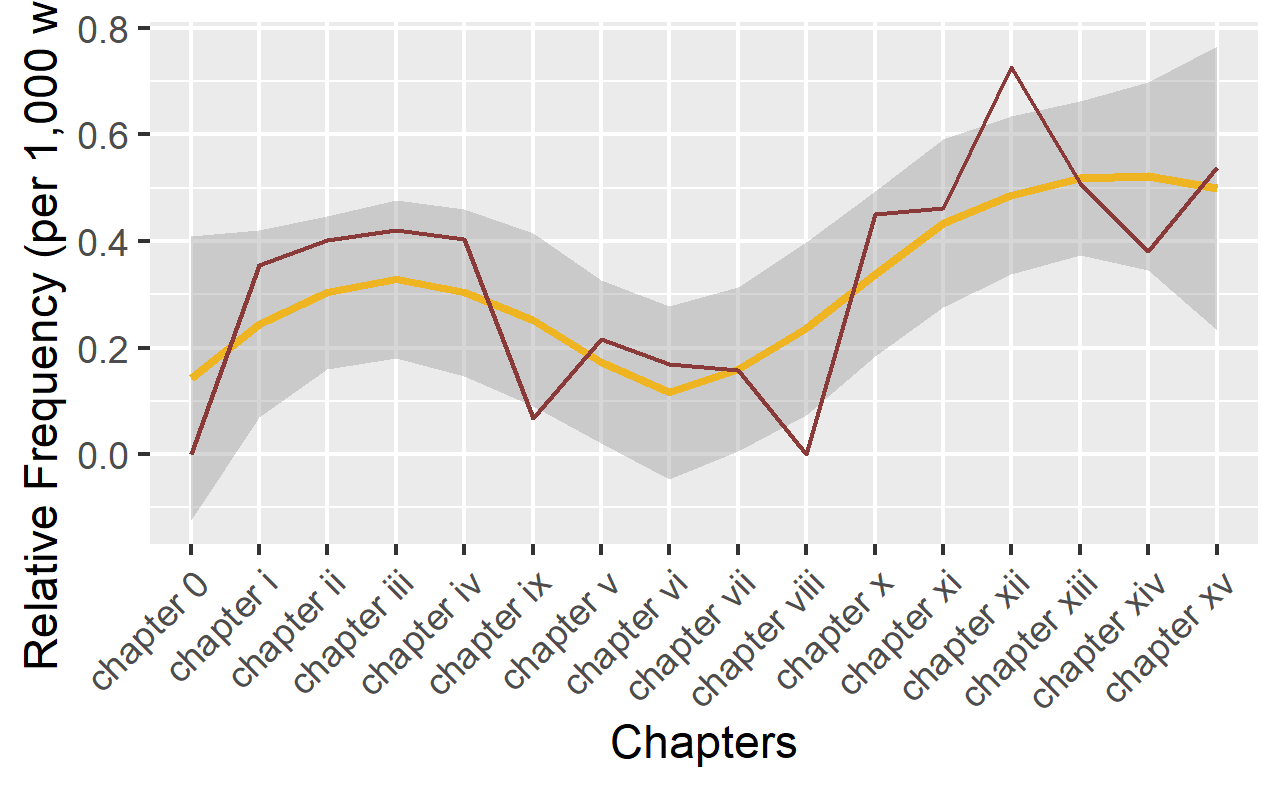
Frequency Analysis
Frequency Analysis is a suit of methods which extract and compare frequencies of different words (tokens and/or types), collocations, phrases, sentences, etc. These frequencies are the often tabulated to show lists of words, phrases, etc. descending by frequency, visualized to show distributions, and/or compared and analyzed statistically to find differences between texts or collections fo texts.
Keyword Analysis
Keyword Analysis refers to a suit of methods that allow to detect words that are characteristic of on text or collection of texts compared to another text/collection of texts. There are various keyness measures such as Log-Likelihood or the term frequency–inverse document frequency (tf-idf).
Lemma (Lemmatization)
Lemma refers to the base form of a word (example: walk, walked, and walking are word forms of the lemma WALK). Lemmatization refers to a annotation process in which word forms are associated with their base form (lemma). Lemmatization is a very common and sometimes useful processing step for further analyses. In contrast to stemming - which is a related process - lemmatization also takes into account semantic differences (differences in the word meaning), while stemming only takes the orthography of words into consideration.
N-Gram
N-grams are combinations/sequences of words, e.g. the sentence I really like pizza! has the bi-grams (2-grams): I really, really like, and like pizza and the tri-grams (3-grams) I really like and really like pizza. N-grams play an important part in natural language processing (e.g. part-of-speech tagging), language learning, psycholinguistics models of language production, and genre analysis.
Natural Language Processing
Natural Language Processing (NLP) is an interdisciplinary field in computer science that has specialized on processing natural language data using computational and mathematical methods. Many methods used in Text Analysis have been developed in NLP.
Network Analysis
Network Analysis is the most common way to visualize relationships between entities. Networks, also called graphs, consist of nodes (typically represented as dots) and edges (typically represented as lines) and they can be directed or undirected networks.
In directed networks, the direction of edges is captured. For instance, the exports of countries. In such cases the lines are directed and typically have arrows to indicate direction. The thickness of lines can also be utilized to encode information such as frequency of contact.
Part-of-Speech Tagging
Part-of-Speech (PoS) Tagging identifies the word classes of words (e.g., noun, adjective, verb, etc.) in a text and adds part-of-speech tags to each word. There are various part-of-speech tagsets, e.g. the Penn Treebank is the most frequently used tagset used for English. A more detailed tutorial on how to perform part-of-speech tagging in R can be found here.
Project Gutenberg
The Project Gutenberg is a excellent resource for accessing digitized literary texts. The Project Gutenberg library contains over 60,000 ebooks that are out of copyright in the US. A tutorial on how to download texts form the Project Gutenberg library using the GutenbergR package can be found here.
Regular Expression
Regular Expressions - often simply referred to as regex - are symbols or sequence of symbols utilized to search for patterns in textual data. Regular Expressions are very useful and widely used in Text Analysis and often different programming languages will have very similar but slightly different Regular Expressions. A tutorial on how to use regular expression in R can be found here and here is a link to a regex in R cheat sheet.
Semantic Analysis
Semantic Analysis refers to a suit of methods that allow to analyze the semantic (semantics) fo texts. Such analyses often rely on semantic tagsets that are based on word meaning or meaning families/categories. Two examples of such semantic tagsets are the URCEL tagset and the Historical Thesaurus Semantic Tagger (alexander2015tagger?) developed at the University of Glasgow.
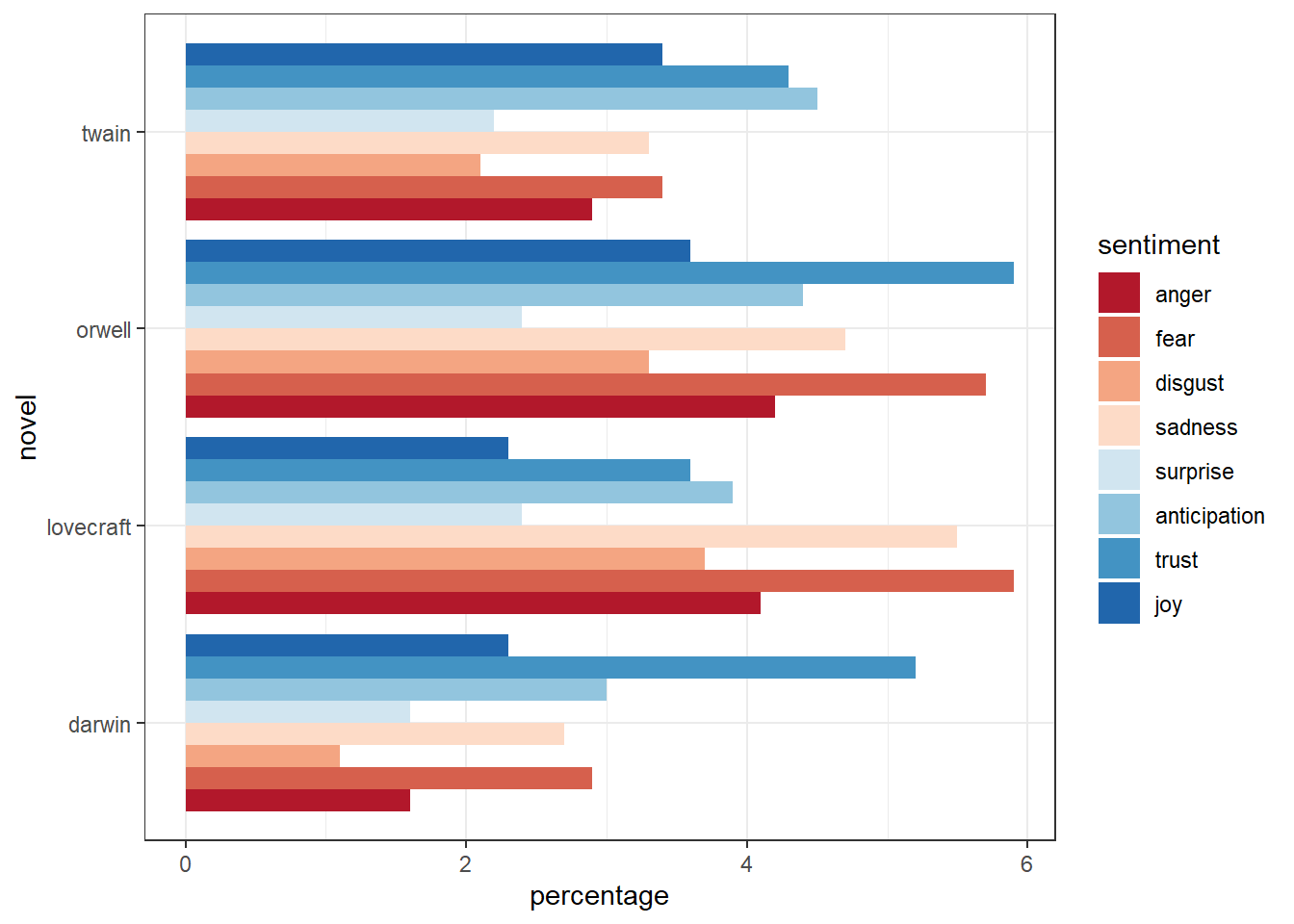
Sentiment Analysis
Sentiment Analysis is a computational approach to determine if words or texts are associated with (positive or negative) polarity or emotions.Commonly, sentiments analyses are based on sentiment dictionaries (words are annotated based on whether they occur in a list of words associated with, e.g., positive polarity or emotion, e.g., fear, anger, or joy. A tutorial on how to perform sentiment analysis in R can be found here.
String
In computational approaches, a string is a specific type of data that represents text and is often encoded in specific format, e.g., Latin1 or UTF8. Strings may also be present in other data types such as lists or data frames. A tutorial on how to work with strings in R can be found here.
Term Frequency–Inverse Document Frequency (tf-idf)
Term Frequency–Inverse Document Frequency is a statistical measure of keyness which reflects how characteristic a word is of a specific text. Term Frequency–Inverse Document Frequency is based on the frequencies of words in a text compared to the frequency of documents in which it occurs
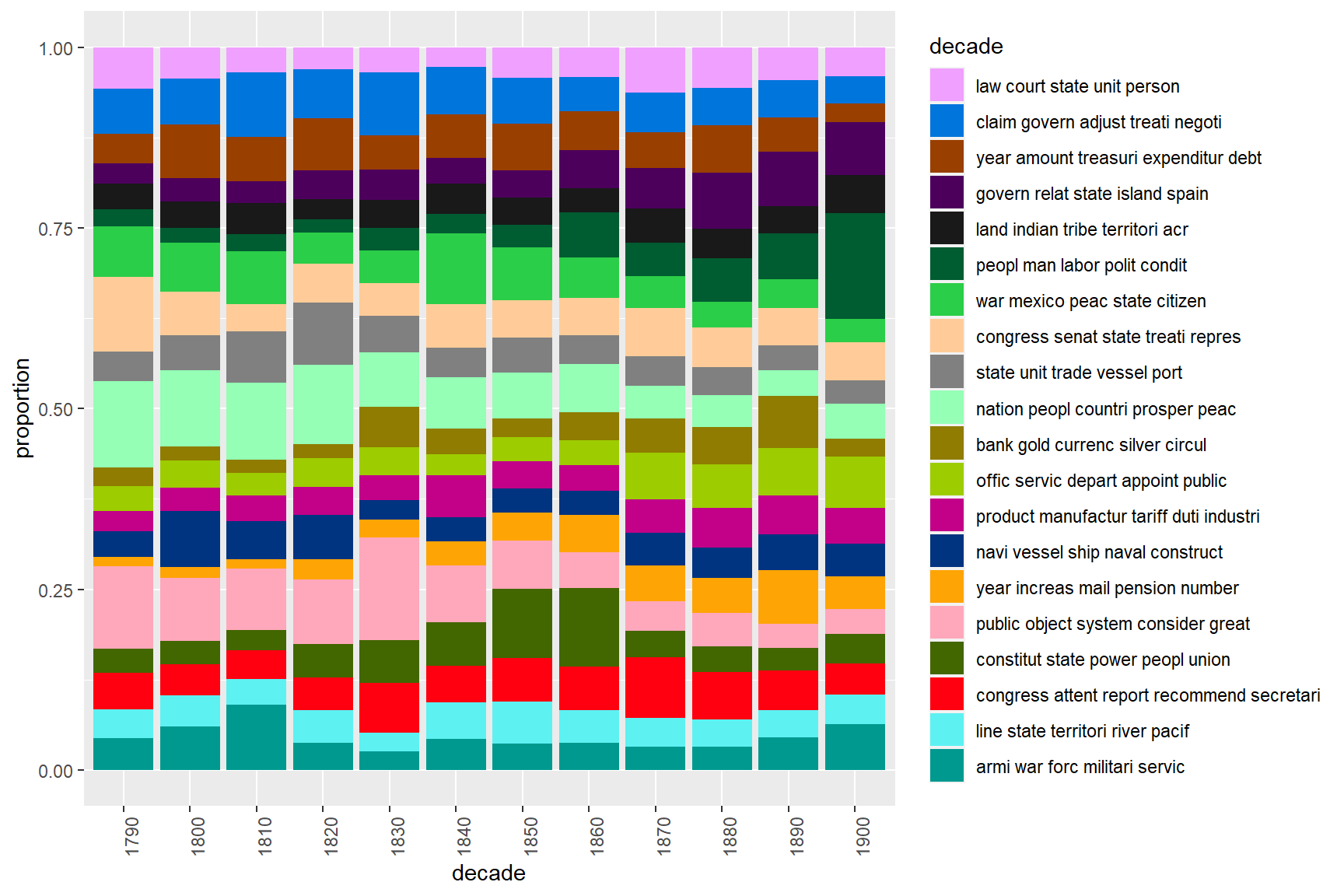
Topic Modeling
Topic modelling is a machine learning method seeks to answer the question: given a collection of documents, can we identify what they are about?
Topic model algorithms look for patterns of co-occurrences of words in documents. We assume that, if a document is about a certain topic, one would expect words that are related to that topic to appear in the document more often than in documents that deal with other topics. Topic model commonly use Latent Dirichlet Allocation (LDA) to find topics in textual data.
There are two basic types of Topic models
supervised or seeded topics models where the researchers provides seed terms around which the LDS looks for topics (collections of correlating terms)
unsupervised or unseeded topic models which try to find a predefined number of topics (collections of correlating terms)
A tutorial on how to work with strings in R can be found here.
Text Analysis at UQ
As LADAL has been established at The University of Queensland, we have listed selected resources on Text Analysis offered by UQ.
The UQ Library offers a very handy and attractive summary of resources, concepts, and tools that can be used by researchers interested in Text Analysis and Distant Reading. Also, the UQ library site offers short video introductions and addresses issues that are not discussed here such as copyright issues, data sources available at the UQ library, as well as social media and web scaping.
In contrast to the UQ library site, the focus of this introduction lies on the practical how-to of text analysis. this means that the following concentrates on how to perform analyses rather than discussing their underlying concepts or evaluating their scientific merits.
Tools versus Scripts
It is perfectly fine to use tools for the analyses exemplified below. However, the aim of LADAL is not primarily to show how to perform text analyses but how to perform text analyses in a way that complies with practices that guarantee sustainable, transparent, reproducible research. As R code can be readily shared and optimally contains all the data extraction, processing, visualization, and analysis steps, using scripts is preferable over using (commercial) software.
In addition to being not as transparent and hindering reproduction of research, using tools can also lead to dependencies on third parties which does not arise when using open source software.
Finally, the widespread use of R particularly among data scientists, engineers, and analysts reduces the risk of software errors as a very active community corrects flawed functions typically quite rapidly.
