Week 2 What is Text Analysis?
Since Text Analysis extracts and analyses information from textual data, it can be considered a derivative of computational linguistics or an application of Natural Language Processing (NLP). As such, Text Analysis represents the application of computational methods in the humanities and thus falls within computational humanities research.
The advantages of Text Analysis include:
Extraction of information from large textual data sets
Replicability and reproducibility of analyses
What is relevant to consider here is that Text Analysis contrasts with traditional or close-reading techniques which do not employ computational means of exploring and analyzing texts. Text Analysis, while allowing for qualitative analysis, builds upon quantitative information, i.e. information about frequencies or conditional probabilities.
Distant Reading is a cover term for applications of Text Analysis that allow to investigate literary and cultural trends by analyzing large amounts of textual data. close reading refers to reading texts in the traditional sense. Text Analysis and distant reading are similar with respect to the methods that are used but with different outlooks. The outlook of distant reading is to extract information from text without close reading, i.e. reading the document(s) itself but rather focusing on emerging patterns in the language that is used.
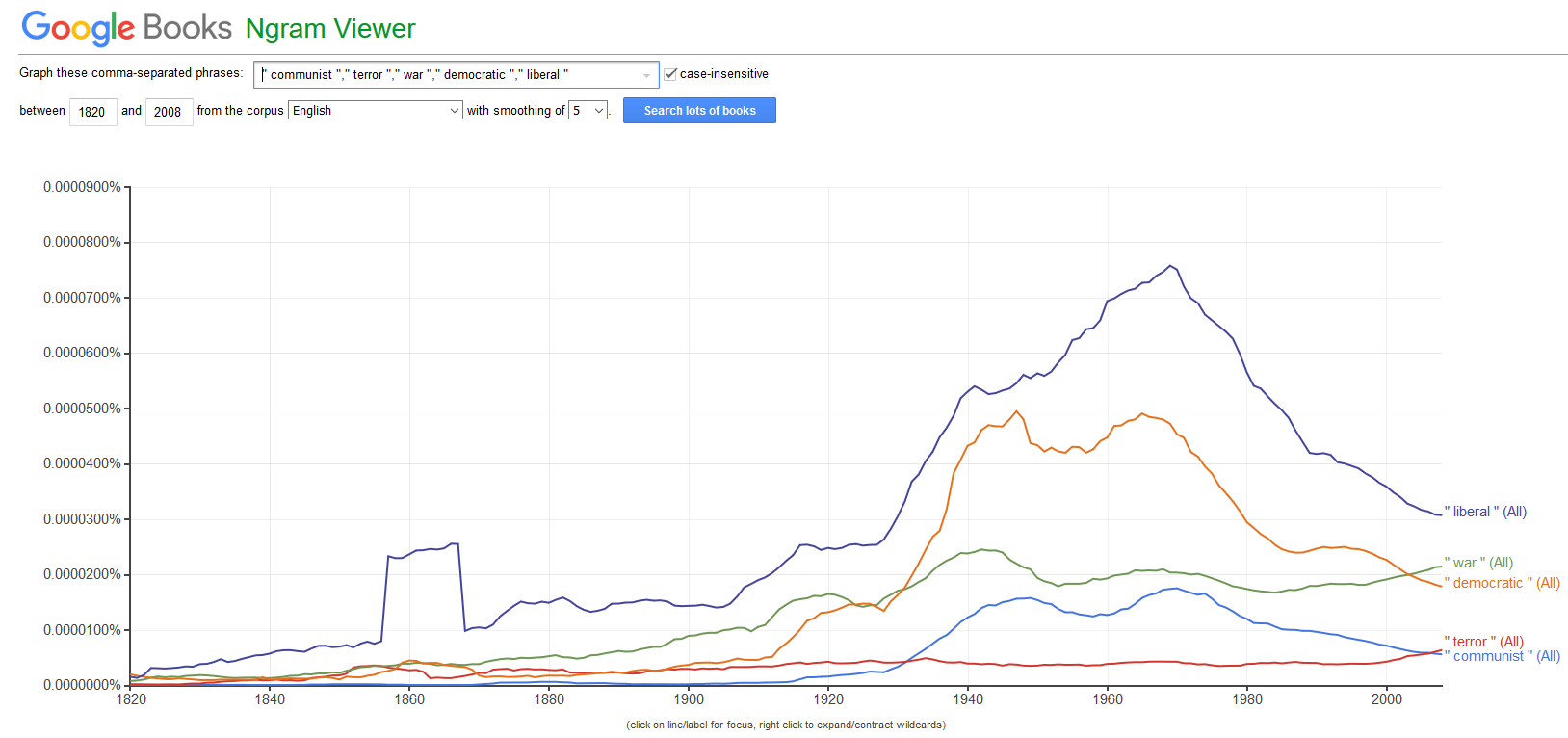
Text Analysis is rapidly gaining popularity in the humanities because textual data is readily available and because computational methods can be applied to a huge variety of research questions. The attractiveness of computational text analysis based on digitally available texts and in their capability to provide insights that cannot be derived from close reading techniques.
While there are some nuances, Text Mining, Text Analytics, and Distant Reading are more or less synonymous with Text Analysis. Regarding these minor differences, Text Analysis is commonly considered more qualitative while Text Analytics is considered to be quantitative. In contrast to Text Analysis, Text Mining is often more data-driven and usually applies methods without substantive supervision or assistance from the human researcher. Distant Reading is used mostly when dealing with literary or academic texts while Text Mining is associated with social media or more generally Big Data. In the following, we use Text Analysis as a cover term encompassing Text Mining, Text Analytics, and Distant Reading.
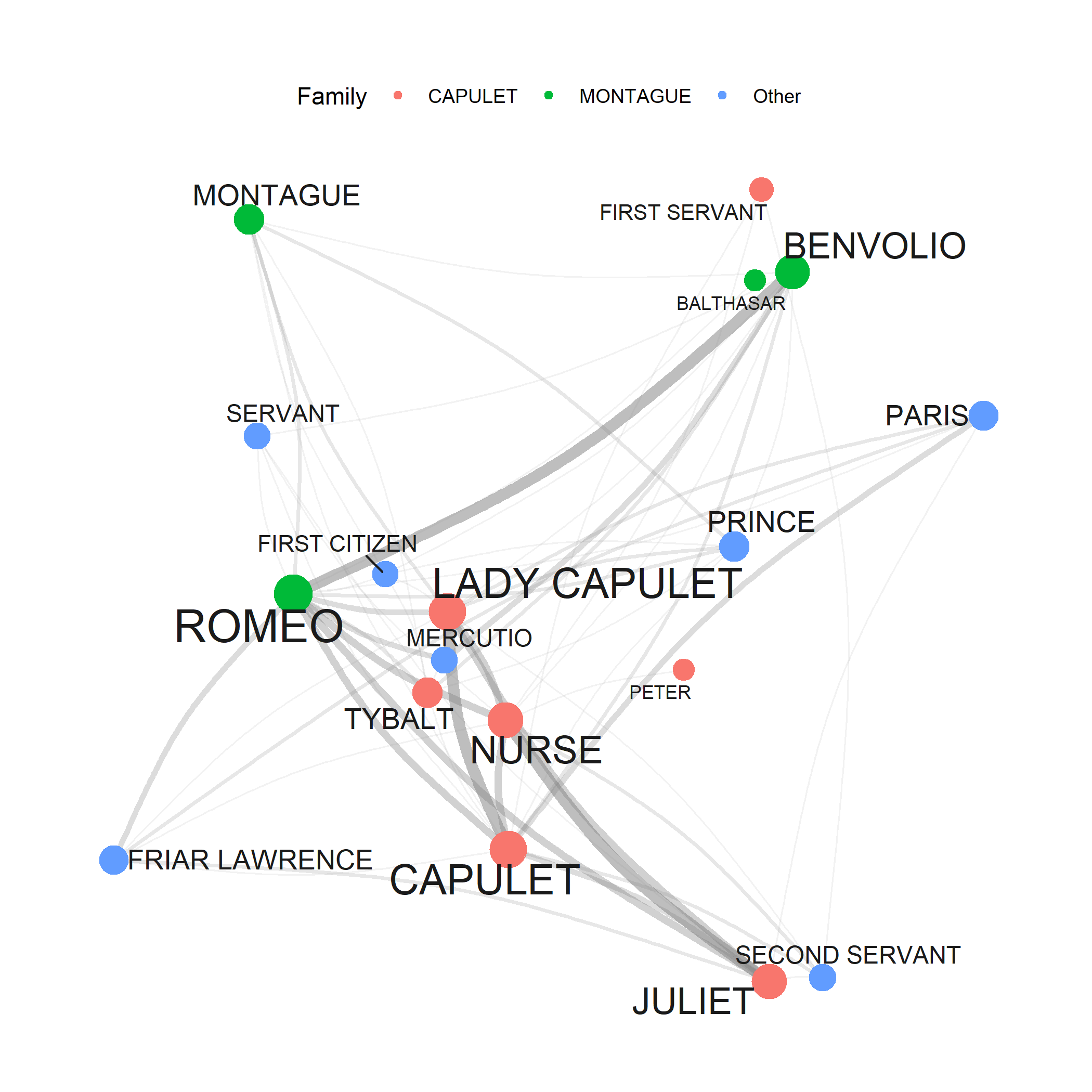
While rapidly growing as a valid approach to analyzing textual data, Text Analysis is critizised for lack of “quantitative rigor and because its findings are either banal or, if interesting, not statistically robust (see here. This criticism is correct in that most of the analysis that performed in Computational Literary Studies (CLS) are not yet as rigorous as analyses in fields that have a longer history of computational based, quantitative research, such as, for instance, corpus linguistics. However, the practices and methods used in CLS will be refined, adapted and show a rapid increase in quality if more research is devoted to these approaches. Text Analysis simply offers an alternative way to analyze texts that is not in competition to traditional techniques but rather complements them.
So far, most of the applications of Text Analysis are based upon a relatively limited number of key procedures or concepts (e.g. concordancing, word frequencies, annotation or tagging, parsing, collocation, text classification, Sentiment Analysis, Entity Extraction, Topic Modeling, etc.). In the following, we will explore these procedures and introduce some basic tools that help you perform the introduced tasks.
Tools versus Scripts
It is perfectly fine to use tools for the analyses exemplified below. However, the aim of LADAl is not primarily to show how to perform text analyses but how to perform text analyses in a way that complies with practices that guarantee sustainable, transparent, reproducible research. As R code can be readily shared and optimally contains all the data extraction, processing, visualization, and analysis steps, using scripts is preferable over using (commercial) software.
In addition to being not as transparent and hindering reproduction of research, using tools can also lead to dependencies on third parties which does not arise when using open source software.
Finally, the widespread use of R particularly among data scientists, engineers, and analysts reduces the risk of software errors as a very active community corrects flawed functions typically quite rapidly.

Text Analysis at UQ
As LADAL has been established at The University of Queensland, we have listed selected resources on Text Analysis offered by UQ.
The UQ Library offers a very handy and attractive summary of resources, concepts, and tools that can be used by researchers interested in Text Analysis and Distant Reading. Also, the UQ library site offers short video introductions and addresses issues that are not discussed here such as copyright issues, data sources available at the UQ library, as well as social media and web scaping.
In contrast to the UQ library site, the focus of this introduction lies on the practical how-to of text analysis. this means that the following concentrates on how to perform analyses rather than discussing their underlying concepts or evaluating their scientific merits.